ELK + Kafka 로그 시스템 알아보기 (1) :: 마이구미
이 글은 ELK + Kafka + Filebeat 를 통한 로그 시스템을 알아본다.
기본적인 흐름을 구성하고 다룰 것이고, 단계로 보면 입문 정도라고 볼 수 있다.
글의 예제는 Docker 를 기반으로 진행되기에, Docker 의 개념이 필요하다.
예제 - https://github.com/hotehrud/log-system
예제는 github 코드를 clone 하고 docker-compose 를 통해 실행하면 동작된다.
실습을 위한 Github 예제에는 기본적인 명령어 팁들이 있다. (README.md)
혹시 실습이 잘 진행되지않으면, docker logs -f 컨테이너이름 을 통해 에러 여부만 잘 파악하면 큰 어려움이 없을 것이다.
글은 다음과 같은 순서로 진행할 것이다.
각 개념에 대해서는 상세히 다루지 않을 것이고, 큰 그림에 초점이 맞추었다.
- ELK
- ELK + Filebeat
- ELK + Filebeat + Kafka
나타내는 순서는 히스토리를 의미하는 것으로 2, 3번은 예제를 통해 확인할 수 있다.
최종 결과물은 3번에 맞추어져있다.
무엇을 의미하는지 알아보자.
ELK Stack 은 Elasticsearch + Logstash + Kibana 를 뜻하는 용어이다.
Elastic 회사에서 제공하는 제품 구성이다. (https://www.elastic.co/kr/)
Logstash
데이터를 수집하고 변환하여 Elasticsearch 에 전송한다.
input, filter, output 으로 구성된 데이터 수집 파이프라인이다.
Elasticsearch
데이터 검색 및 분석을 담당하는 엔진이다.
Kibana
Elasticsearch 에 저장된 데이터를 시각화해주는 웹 인터페이스이다.

각 서버의 로그들을 logstash 에서 로그를 수집 및 변환하여 Ship 역할로 Elasticsearch 로 전송한다.
그리고 Elasticsearch 데이터 기반으로 Kibana 에서 시각적으로 보여준다.
위 그림의 구성은 docker-elk 를 통해 확인할 수 있다.
시간이 흘러 Elastic 에서는 사용자 요구사항들을 적용하여 Beats 를 추가하였다.
ELK + Beats 를 합친 용어로 Elastic Stack 이라고 불린다.
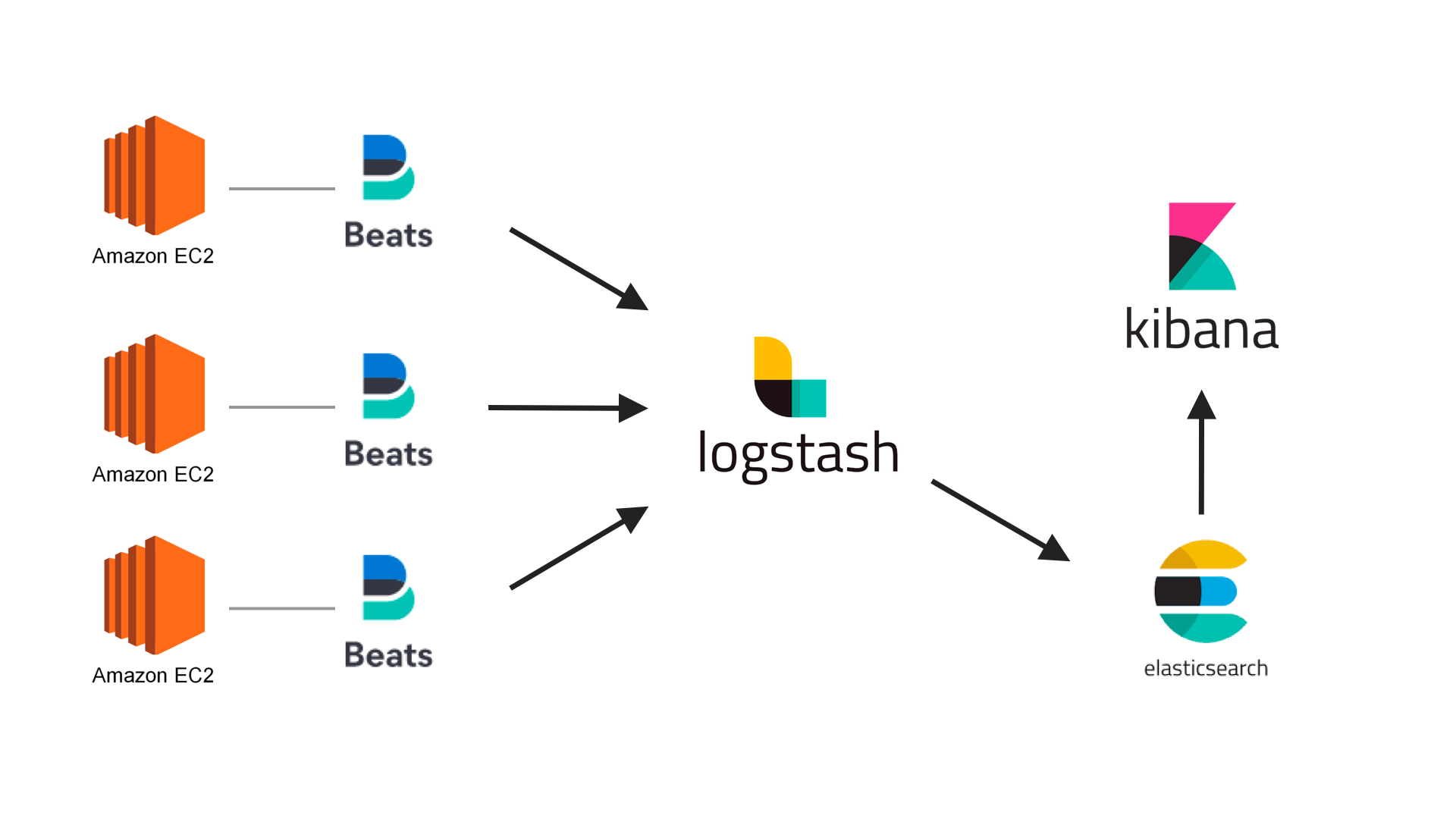
Beats
경량 데이터 수집기로 로그 파일을 저장하고 데이터 Ship 역할로 Logstash 로 전송한다.
적은 메모리 사용으로 리소스 절감이 가장 큰 장점이라고 한다.
Logstash 는 다양한 로그를 수집 및 변환하여 Elasticsearch 전송한다.
그리고 Elasticsearch 데이터 기반으로 Kibana 에서 시각적으로 보여준다.
예제를 통해서 확인해보자. https://github.com/hotehrud/log-system
코드는 최종 결과물인 3번을 위한 것임으로, tag 명 "filebeat" 를 checkout 해야한다.
$ git checkout tags/filebeat
docker-elk 를 기반으로 app, filebeat 를 추가했다.
app 은 Node.js 기반 웹 서버, 로그 저장을 위한 filebeat 를 의미한다.
app 예제 코드 (자세한건 Github 참고)
const logDir = `${appRoot}/logs`;
웹 서버의 로그는 최상위 루트의 logs 디렉토리에 저장된다.
* morgan 기반으로 웹 서버 접근 시 로그는 req.log 와 날짜별 rotate 파일에 기록된다.
Dockerfile (filebeat)
ARG ELK_VERSION
FROM docker.elastic.co/beats/filebeat:${ELK_VERSION}
COPY filebeat.yml /usr/share/filebeat/filebeat.yml
USER root
RUN mkdir /var/log/server
RUN chown root:filebeat /usr/share/filebeat/filebeat.yml
USER filebeat
로그가 저장되는 파일 경로를 위해 /var/log/server 디렉토리를 생성한다.
docker-compose.yml
....
app:
build:
context: ./app
volumes:
- log-volume:/app/logs
ports:
- "3000:3000"
filebeat:
build:
context: ./filebeat
args:
ELK_VERSION: $ELK_VERSION
volumes:
- log-volume:/var/log/server
networks:
- elk
depends_on:
- logstash
networks:
elk:
driver: bridge
volumes:
elasticsearch:
log-volume:
웹 서버의 로그는 app/logs 에 저장된다.
filebeat 는 도커 이미지에서 /var/log/server 디렉토리를 생성한다.
볼륨 컨테이너 log-volume 를 통해 로그 수집 경로를 공유하게한다.
멀티 컨테이너 환경에서의 각 컨테이너간 네트워크 공유를 위해 networks 로 연결해준다.
filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/server/req.log
fields:
topic: req-log
output.logstash:
hosts: ["logstash:5044"]
paths 에 설정된 경로를 지켜보게 된다.
30초(디폴트)마다 모니터링을 통해 설정된 output 경로인 logstash 에 전송하게 된다.
logstash.conf
input {
beats {
port => 5044
}
}
도커 컨테이너 실행 후 localhost:3000 에 접근하면 웹 서버 로그를 쌓인다.
쌓인 로그는 localhost:5601 키바나를 통해 확인할 수 있다.
이번에는 Elastic Stack(ELK + Beats) 에서 Kafka 를 연동하는 것이다.
Kafka 를 도입하는 많은 이유 중 하나는 트래픽이 몰리면 Logstash, Elasticsearch 만으로는 부하를 견디기 힘들다고한다.
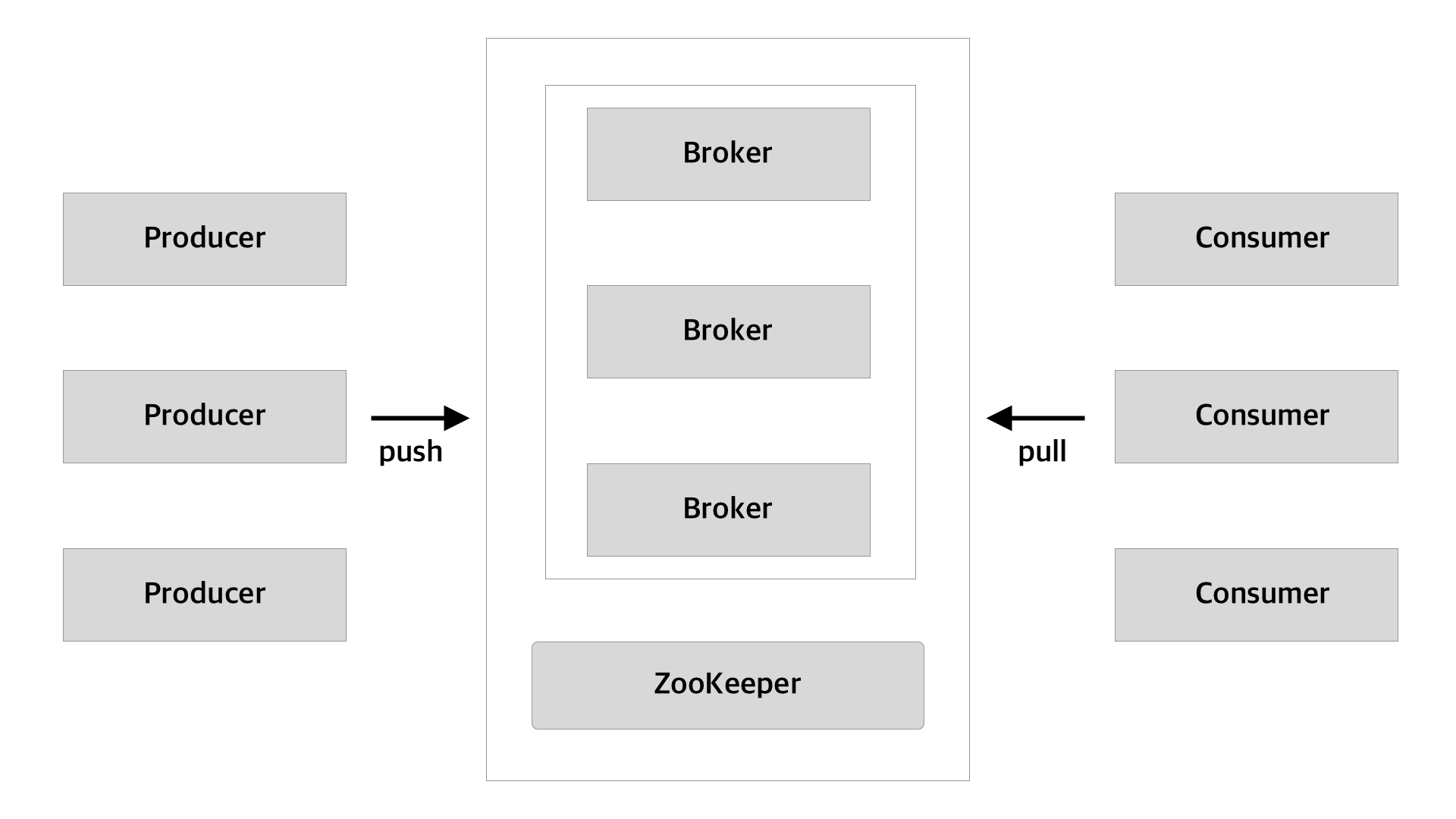
*일반적으로 최소 주키퍼 3대, 카프카 3대로 구성한다고 하는데 그림이나 예제에서는 각 1대로 구성하였다.

Kafka
Pub-Sub 모델을 가지는 분산 메시징 플랫폼이다.
기존 메시징 시스템처럼 Broker 가 Consumer 에게 직접 메시지를 전송하는 방식이 아니다.
Kafka 는 Consumer 가 Broker 로부터 직접 메시지를 가져가는 방식이다.
- Producer - 메시지 발행 ex) filebeat
- Consumer - 메시지 구독 ex) logstash
- Broker - Kafka 서버
- Topic - 저장되는 데이터를 구분하는 용도 ex) DB 테이블
- Zookeeper - Kafka 서버 관리
이전 단계에서는 Filebeat 에서 Logstash 로 데이터를 전송했다.
Kafka 를 추가함으로써, Filebeat 는 Kafka 로 데이터를 전송하고 Logstash 에서 Kafka 에 있는 데이터를 가져가게 된다.
이전 단계와 비교해서 역할이 달라졌기 때문에 Filebeat output 과 Logstash input 수정이 필요하다.
filebeat.yml
output.kafka:
hosts: ["kafka:9092"]
topic: 'log'
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 1000000
topic 을 명시하고 output 을 Kafka 로 정의한다.
logstash.conf
input {
kafka {
bootstrap_servers => "kafka:9092"
topics => ["log"]
}
}
"log" 라는 topic 명을 구독하여 메시지를 가져와서 Elasticsearch 에 전송하고 Kibana 를 통해 시각화해준다.
기본적인 흐름을 다뤄보았다.
추후 실제로 서비스에 적용해보면서 새롭게 얻는 경험과 지식들을 다음 편으로 남겨보도록 예정이다.
잘못된 내용이 있다면, 댓글로 남겨주시면 감사히...
참고 링크
kafka-docker https://github.com/wurstmeister/kafka-docker
Elastic Stack https://blog.eunsukim.me/posts/build-logging-system-with-docker-elk-filebeat-nodejs
Elastic Stack + kafka https://investment-engineer.tistory.com/6?category=979835
Filebeats vs Logstash https://sabarada.tistory.com/46