SPA 에서 SEO 적용하기 :: 마이구미
이 글은 SPA(Single Page Application) 에서 SEO 를 적용하는 방법을 다룬다.
SSR 가 아닌 CSR 로 구현된 페이지에서 SEO 적용은 까다롭다.
이를 위한 방안으로 re-rendering 이라고 불리는 방식이 존재한다.
* 동적 라우터를 위한 방식을 알아본다. ex) product/:id
대부분의 BtoC 서비스라면, SEO 는 필수적이다.
우리는 원하는 페이지들이 구글, 네이버, 다음과 같은 검색 서비스에 노출되길 원할 것이고,

카카오톡, 페이스북과 같은 서비스에 공유될 때 원하는 썸네일, 텍스트 등을 노출하길 원한다.
이를 위해서는 html 의 요소인 <title> 태그와 <meta> 태그를 활용해야한다.
<html>
<title>Hi!</title>
<meta name="title" content="" />
<meta name="description" content="" />
<meta property="og:url" content="" />
<meta property="og:type" content="website" />
<meta property="og:title" content="" />
<meta property="og:description" content="" />
<meta property="og:image" content="" />
</html
위와 같은 태그들을 통해 위처럼 검색엔진 노출이나 공유할 때 원하는 정보를 인식하여 노출할 수 있게 된다.
태그들을 활용해서 알아서 잘 노출되었으면 좋겠지만,
SSR(서버 사이드 렌더링) 가 아닌 CSR(클라이언트 사이드 렌더링) 방식으로 구현했을 때 이슈가 발생한다.
개인적인 의견으로는 SSR 와 CSR 을 선택하는 가장 큰 영향을 주는 것이 SEO 라고 본다.
* React, Vue 등을 사용해 CSR 방식으로 구현을 하곤한다.
CSR 방식으로 구현하면 왜 문제가 되는가?
우선 SSR 과 CSR 을 비교해본다.
각 페이지에 해당하는 /, /a, /b 가 있다고 가정한다.

서버는 매번 새로운 HTML 파일을 응답하여 이를 바탕으로 매번 새로운 페이지를 그려준다.
각 페이지는 서로 다른 HTML 파일을 의미한다.

반면 CSR 의 경우에는 여러개의 페이지로 존재하고 보이더라도, 내부적으로는 1개의 HTML 파일이다.
클라이언트가 서버는 Ajax 와 같은 요청을 서버에 보내고 서버는 JSON 형태의 데이터를 내려준다.
그리고 클라이언트에서 응답 데이터를 기반으로 새로운 페이지가 아닌 그 부분에 대해서만 업데이트한다.
이를 기반으로 크롤러 입장에서 바라보자.
크롤러는 SSR 방식의 각 페이지에 접근하면 각 페이지의 html 정보를 각각 수집하게 된다.

반면 CSR 방식의 각 페이지에 접근한다면, 각 페이지에 대한 정보는 1개의 HTML 파일인 루트 페이지의 html 정보만을 수집하게 된다.
즉, 모든 페이지들은 크롤러 입장에서는 하나의 루트 페이지(/)로 인식할 뿐이다.

쉬운 이해를 위해 직접 쉽게 확인해볼 수 있다.
CSR 방식으로 구현된 프로젝트에서 다음을 실행해보자.
- "/" 페이지에서 우클릭 => "페이지 소스 보기" 클릭 => HTML 코드 확인.
- "/a" 페이지에서 우클릭 => "페이지 소스 보기" 클릭 => HTML 코드 확인.
- "/b" 페이지에서 우클릭 => "페이지 소스 보기" 클릭 => HTML 코드 확인.
- "/c" 페이지에서 우클릭 => "페이지 소스 보기" 클릭 => HTML 코드 확인.
모두 똑같은 파일이 나올 것이다.
이로 인해, 모든 페이지는 하나의 HTML 파일의 정보를 바라보고 있어, 검색서비스 노출 및 SNS 공유 기능 등이 원하는대로 동작할 수 없다.
크롤러가 왜 루트 페이지의 데이터만을 수집하는 지를 확인할 수 있다.
* 검색서비스마다 검색엔진의 동작은 모두 다르다. 구글의 경우 스크립트를 실행하고 비동기 요청에 의한 처리까지 분석할 수 있다.
어떻게 특정 페이지의 정보를 수집할 수 있게 하는가?
SSR 처럼 각 원하는 페이지에 해당하는 html 파일과 같은 형태가 존재해야만, 기대했던 대로 크롤러가 수집한다.
즉, 각 라우터에 해당하는 index.html 파일을 만들어주면 된다.
React 를 기준으로 react-helmet 과 react-snap 를 함께 사용할 수 있다.
react-helmet 을 통해 메타 태그를 셋팅하고, react-snap 을 통해 index.html 을 생성한다.
<Route path="/a" />
<Route path="/b" />
<Route path="/c" />
정적 라우터인 경우에는 쉽게 적용해서 사용할 수 있다.
- /a/index.html
- /b/index.html
- /c/index.html
위와 같은 경로에 HTML 파일이 생성된다.
하지만 위와 같은 형태의 라우터는 정적 라우터라고 표현해본다.
그렇다면, 동적 라우터도 처리가 가능한가?
<Route path="/content/:id" />
react-snap 와 같은 라이브러리들은 내부적으로 자동으로 브라우저를 제어해서 해당하는 페이지가 로드된 후에 크롤링해서 index.html 를 생성한다.
이러한 흐름에서 a, b, c 라는 페이지는 명확하게 알 수 있지만, 아시다시피 현재로선 /:id 는 id 가 무엇이고, 얼마나 있는지 전혀 알 수가 없다.
동적 라우터는 어떤 URL 이 존재하는지 파악할 수 없기에 위 방식으로는 불가능하다.
동적 라우터에 대한 처리는 어떻게 해야하는가?
:id 에 해당하는 데이터들을 위한 별도의 API 나 파일과 같은 형태가 필요하다.
그 데이터를 기반으로 지금껏 얘기했던 같은 이유로 index.html 파일을 생성해주면 된다.
여기서는 prerender-spa-plugin 을 활용한다.
친절하게 각 환경에서의 예제를 볼 수 있다.
웹팩을 기반으로 빌드하는 시점에 각 동적 페이지들을 로드한 후, 그것을 기반으로 크롤링하여 index.html 을 생성하는 방식이다.
prerender-spa-plugin 은 어떻게 사용하는가?
웹팩 플러그인이라고 생각하면 된다.
new PrerenderSPAPlugin({
"routes": [],
"staticDir": path.join(__dirname, "build"),
"postProcess"(renderedRoute) {},
"renderer": new PrerenderSPAPlugin.PuppeteerRenderer({
"args": ["--no-sandbox", "--disable-setuid-sandbox"],
"headless": false
})
})
index.html 을 생성할 페이지에 해당하는 데이터들을 "routes" 에 넣어주면 된다.
ex) "/content/1", "/content/2", ...
예를 들어 다음과 같다.
- 빌드하는 시점에 쉘 스크립트를 실행한다.
- 쉘 스크립트는 API 를 호출하여 동적 페이지에 대한 데이터를 가져온다.
- 데이터를 기반으로 파일을 생성한다.
- 생성된 파일을 읽어서 PrerenderSPAPlugin 의 routes 에 넣어준다.
// shell script
OUTPUT=$(curl --location --request GET 'https://api.com/seo')
echo "$OUTPUT" > seo.json
// seo.json
[
{
"route": "/content/1",
"title": "",
"description": "",
"imageUrl": "",
"url": ""
},
{
"route": "/content/2",
"title": "",
"description": "",
"imageUrl": "",
"url": ""
}
]
// config-overrides.js
const routes = require('./seo.json');
module.exports = (config, env) => {
if (env === 'production') {
config.plugins = config.plugins.concat([
new PrerenderSPAPlugin({
routes: [].concat(routes.map(item => item.route)),
staticDir: path.join(__dirname, 'build'),
postProcess(renderedRoute) {
let { html, route } = renderedRoute;
const { title, description, imageUrl, url } = routes.find(
item => item.route === route
);
const metaData =
`<title>${title}</title>` +
`<meta name="title" content="${title}" />` +
`<meta name="description" content="${description}" />` +
`<meta property="og:url" content="${url}" />` +
`<meta property="og:type" content="website" />` +
`<meta property="og:title" content="${title}" />` +
`<meta property="og:description" content="${description}" />` +
`<meta property="og:image" content="${imageUrl}" />` +
`<meta property="twitter:card" content="${imageUrl}" />` +
`<meta property="twitter:url" content="${url}" />` +
`<meta property="twitter:title" content="${title}" />` +
`<meta property="twitter:description" content="${description}" />` +
`<meta property="twitter:image" content="${imageUrl}" />`;
const start = html.indexOf('<head>') + '<head>'.length;
html = html.slice(0, start) + metaData + html.slice(start);
renderedRoute.html = html;
return renderedRoute;
},
renderer: new PrerenderSPAPlugin.PuppeteerRenderer({
maxConcurrentRoutes: 2,
args: ['--no-sandbox', '--disable-setuid-sandbox'],
headless: false
})
})
]);
}
return config;
};
동적 URL 리스트를 통해 각 HTML 파일에 맞는 데이터를 웹팩 쪽에서 처리하는 모습이다.
* 처음에는 react-helmet 을 통해 메타태그를 셋팅하고 PrerenderSPAPlugin 가 페이지를 긁어서 생성하려고 했다.
때론 랜더링 시점이 맞지 않는 경우도 발생했고, 내부 로직에서 분리할 수 있으면 하는게 낫겠다 생각했다.
결과적으로는 빌드 시 빌드된 파일들과 함께 셋팅된 각 index.html 들이 함께 생성된다.
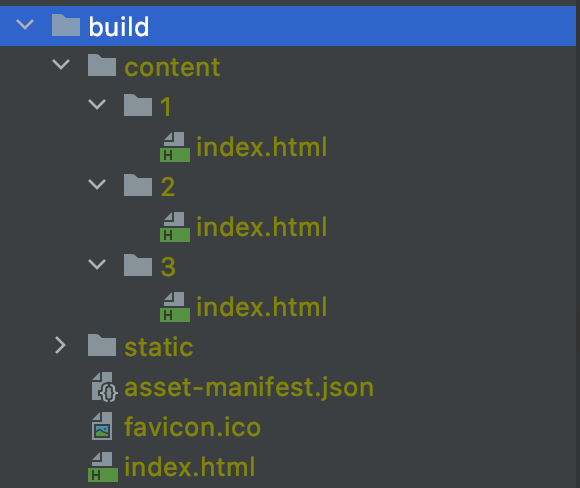
위와 같은 형태로 배포가 된다면, 각 페이지에 해당하는 HTML 파일을 가지게 된다.
이로써, 각 페이지는 검색엔진이나 공유하는 기능 등에서 원하는 데이터를 포함하고 있다.
또 하나의 이슈
마지막으로 작업해줘야하는 문제가 한가지 남아있다.
/content/3/index.html 형태로 파일이 존재하기 때문에 /content/3/index.html 로 접근해야한다.
/content/3 이러한 형태로 크롤러가 접근하거나 링크를 공유할 때 문제가 발생한다.
이를 위해 /content/3 으로 접근 시 /content/3/index.html 의 리소스를 내려주는 작업을 해줘야한다.
예를 들어 CloudFront 의 경우에는 Lambda@Edge를 통해 쉽게 해결할 수 있다.
'use strict';
exports.handler = (event, context, callback) => {
/*
* Expand S3 request to have index.html if it ends in /
*/
const request = event.Records[0].cf.request;
if ((request.uri !== "/") /* Not the root object, which redirects properly */
&& (request.uri.endsWith("/") /* Folder with slash */
|| (request.uri.lastIndexOf(".") < request.uri.lastIndexOf("/")) /* Most likely a folder, it has no extension (heuristic) */
)) {
if (request.uri.endsWith("/"))
request.uri = request.uri.concat("index.html");
else
request.uri = request.uri.concat("/index.html");
}
callback(null, request);
};
잘 배포가 되었다면, metatags.io/ 과 같은 서비스를 통해 수집 여부를 파악할 수 있다.
마무리
매번 동적 페이지가 추가될때마다 그에 맞는 HTML 파일을 생성하는 방식이다.
이러한 큰 틀에서 효율적인 방식을 점차 적용해나가면 되나 결국은 SSR 방식에 비해서는 다소 매끄럽지 못하다.
많은 동적 페이지를 요구하고 SEO 최적화가 필요한 서비스라면 CSR 방식은 다소 무리라고 판단된다.
* 잘못된 내용이나 다른 방안이 있다면, 알려주시면 감사할 따름입니다.